Qi C R, Liu W, Wu C, et al. Frustum pointnets for 3d object detection from rgb-d data[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 918-927.
1. Overview
- Previous method focus on images or 3D voxels
- Treat RGB-D data as 2D maps for CNN
- Learning in 3D space can better exploit the geometric and topological structure of 3D space and apply transformation
In this paper, it proposed Frustum PointNet
- operate on raw point clouds by RGB-D scans
- leverage both 2D detection and 3D object localization
- key challenge. efficientlypropose possible localtions of 3D obj in 3D space

2D proposal→frustum proposal→segmentation→3D box estimation

coordinate normalization

1.1. Related Works
- Front View Image Based Methods
represent depth data as 3D maps - Bird’s Eye View Based Methods
MV3D. project LiDAR point cloud to bird’s eye view and train RPN for 3D bounding box proposal - 3D Based Methods
- Deep Learning on Point Clouds
1.2. Problem Definitions
- depth data. obtained from LiDAR or indoor depth sensors and represented as a point cloud
- the projection matrix is known. can get a 3D frustum from a 2D image region
- 3D box is parameterized by size (h, w, l), center (c_x, c_y, c_z) and orientation (Θ, φ, ψ).
only consider heading angle Θ in this paper.
1.3. Dataset
- KITTI (outdoor). RGB + LiDAR point cloud (sparse due to distence)
- SUN-RGBD (indoor). RGB-D (dense)
general framework to sparse cloud and dense cloud.
2. Frustum PointNets

2.1. Frustum Proposal
The resolution of data produced by moist 3D sensors (especially real-time depth sensors) is still lower than RGB image from commodity camera.
- 2D RGB detector. Fast R-CNN, FPN, focal loss
- with known camera projection matrix, 2D box can be lifted to frustum
- rotate. center axis of frustum if orthogonal to the image plane
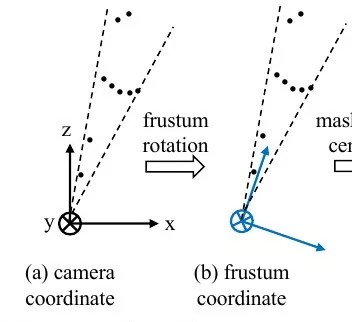
2.2. 3D Instance Segmentation

2.2.1. V1 PointNet

2.2.2. V2 PointNet++

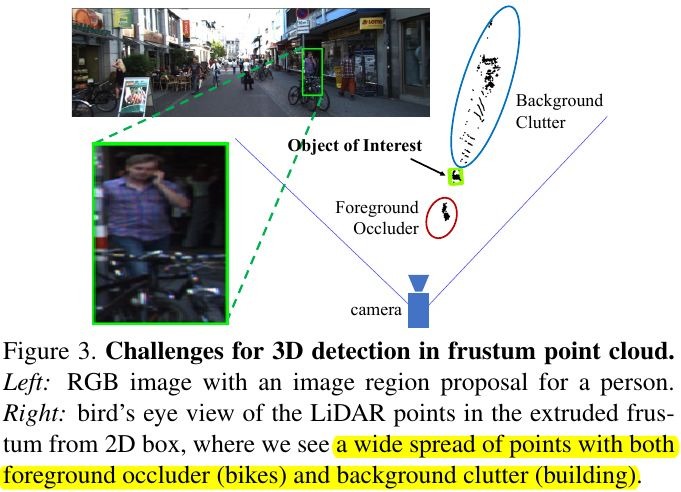
- directly regress 3D object location from a depth map using 2D CNN is not easy, as occluding objects and background clutter
segmentation (binary classification of pixel level) in 3D point cloud is much more natural
leverage the semantics from 2D detector (one-hot class vector)
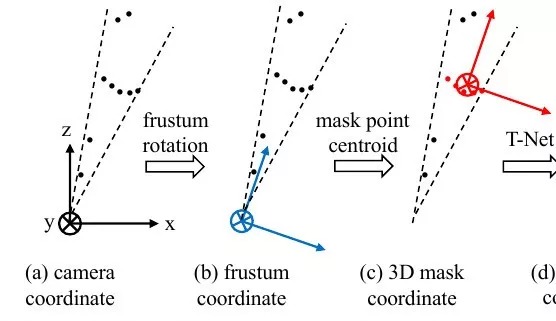
segmentation network can use this prior to find geometries of that category.- coordinate normalization. transform the point cloud by subtracting XYZ values of centroid
- mask the input frustum
2.3. Amodal 3D Box Estimation
2.3.1. T-Net

- the origin of the mask coordinate frame may be far from the amodal box center
- STN (no direct supervision) vs T-Net (explicitly supervise)
2.3.2. Box Estimation PointNet
V1 PointNet

V2 PointNet++

box center residual prediction. combined with the previous center residual from the T-Net and the masked points’ centroid to recover an absolute center

pre-defined NS size templates (3:height, width, length) and NH equally split angle (Θ) bins (NS scores for size, NH socres for heading)
- output dimension. 3(center point) + 4xNS + 2xNH
2.4. Multi-task Loss

- L_{c1-reg}. center of T-Net
- L_{c2-reg}. center of box estimation net
- L_{h-cls}, L_{h-reg}. heading angle prediction
- L_{s-cls}, L_{s-reg}. size prediction
- L_{corner}. corner loss for joint optimization pf box parameters
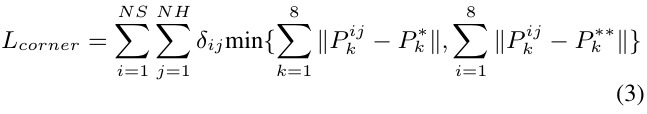
Optimized for final 3D box accuracy (center, size and heading) have separate loss terms. And they should be jointly optimized→corner positions are jointly determined by center, size and hearding.
- for each of NS x NH box
- only foucs on the gt size/heading class
- sum of the distance between the eight corners of prediction and gt box
To avoid large penalty from flipped heading estimation, further compute p from the flipped gt box and use minimum** of them.
3. Experiments
3.1. Comparison




3.2. Ablation Study
3.2.1. 2D vs 3D
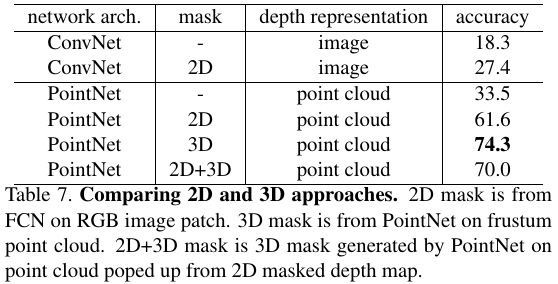

- contains clutter and background
3.2.2. contains clutter and background
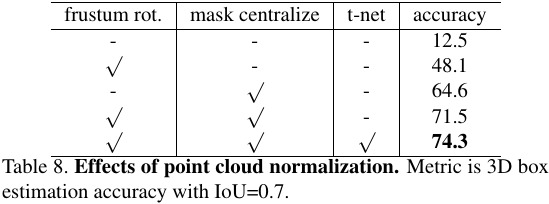
- Frustum rotation and mask centroid subtraction are critical
3.2.3. Loss Function

3.2.4. PointNet Version

3.3. Failure Case
- inaccurate pose and sparse cloud (less than 5 points)
- multiple instances from the same category in a frustum
- 2D detector misses objects due to dark light or strong occlusion